
Product

Solutions
Resources
About Us
Use Cases
Contact Us

.png)
Part 3 of 5. ← Part 2: The Noise Problem · Part 4: Thresholds and Active Learning → · Series index
Parts 1 and 2 covered the quality of comparison: using the right signals and removing noise before matching. This part covers the quantity problem: how many comparisons you actually have to make, and how to make that number tractable.
The scale problem in fuzzy matching is simple to state and brutal in practice: to find every matching pair in a dataset of N records, you potentially need to compare every record against every other. That's O(n²) — and it gets unmanageable fast.
Let's put numbers on it.
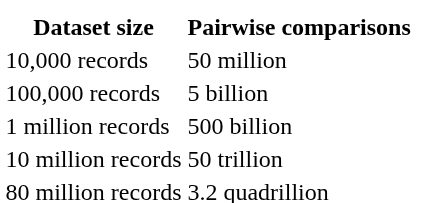
Even if each comparison takes a single microsecond, 50 trillion comparisons take 50 million seconds — about 578 days. With a 96-core cluster, you get that down to six days. Still not a pipeline you run nightly.
This isn't a hypothetical. Enterprise CRM databases routinely exceed a million records. Healthcare patient registries can exceed 10 million. National voter rolls and financial transaction datasets can reach 80 million or more. And this is before cross-source linking, where you need to compare records in dataset A against records in dataset B.
Brute-force pairwise comparison is off the table for any serious production use case. The solution is blocking.
Blocking is the technique of narrowing down candidate pairs before comparison. Rather than comparing every record against every other, you first group records into candidate buckets — "blocks" — and only compare records within the same block.
The intuition is that records which could plausibly match should share at least one attribute in common. Records with completely different first letters of surname are unlikely to match. Records with completely different zip codes are unlikely to match (unless there's an address error). Records with completely different year-of-birth values are unlikely to match.
A blocking key exploits this intuition. Common blocking keys include:
Records that share a blocking key are placed in the same block and compared against each other. Records that share no blocking key are never compared — and therefore can never be found to match.
This is the efficiency gain: instead of N² comparisons, you have a much smaller number of within-block comparisons. In practice, a well-designed blocking strategy can reduce the comparison space by 99% or more.
Here's the problem. If two records that should match don't share any blocking key, they never get compared. The match is permanently missed. You get a false negative — and because the record pair was never compared, you have no visibility into the miss. The system doesn't report "we couldn't find a match for this record". It just silently produces an incomplete output.
This is the defining failure mode of blocking, and it's significantly more dangerous than false positives for most applications. A false positive (incorrectly merging two distinct entities) is usually detectable and correctable. A false negative (missing a true match) is silent and cumulative: your entity resolution output looks fine while quietly being incomplete.
Silent false negatives arise from:
Blocking on a single field with high null rates. If you block on surname initial but 15% of your records have no surname, 15% of your records are never compared against anything.
Blocking on a field with systematic variation. If you block on soundex code of first name, but one source always records formal names ("William") while the other uses nicknames ("Bill"), the soundex codes don't match and the records are never compared.
Geographic or demographic bias in training data. If your blocking rules were derived from a dataset that only covers one region, those rules may be too narrow to work correctly on a more diverse dataset. This is one of the key failure modes the Zingg verifyBlocking documentation flags explicitly: "A user adds significantly larger training samples compared to the labelling learnt by Zingg. The manually added training samples may have the same type of columns and blocking rules learnt are not generic enough. For example, providing California state only training data when the matching is using the State column and data has multiple states."
Over-narrow blocking on a noisy field. If your blocking key is the first three characters of surname, but surname is noisy (typos, multiple spellings), then legitimate matches with different surname spellings fall into different blocks.
Designing blocking keys that are both efficient (reducing comparisons substantially) and complete (not missing too many true matches) is a genuine engineering challenge, and it gets harder as your data gets messier.
The traditional approach to blocking is hand-crafted rules: a data engineer examines the data and decides that blocking on soundex of surname plus first two digits of postcode is a reasonable strategy. This works when you know your data well and it's relatively clean.
It breaks down when: - The data is messier than expected - The data comes from multiple source systems with different conventions - The data distribution changes over time (new geographies added, new naming patterns, different null rates) - You're matching across datasets with different field semantics
The alternative is to learn the blocking model from labeled training data. Rather than encoding your assumptions about which fields make good blocking keys, you let the model observe which labeled matching pairs share which field values, and derive blocking rules from that evidence.
This is what Zingg does. From the Zingg models documentation: "Zingg learns a clustering/blocking model which indexes near similar records. This means that Zingg does not compare every record with every other record. Typical Zingg comparisons are 0.05–1% of the possible problem space."
0.05–1% of the comparison space means that for an 80-million record dataset, Zingg is doing roughly 40,000 to 800,000 comparisons per record rather than 80 million. That's what makes the performance numbers possible:
The learned blocking model adapts to your data rather than encoding assumptions about it. If your data has high null rates in certain fields, the blocking model learns to route around them. If abbreviations are common in one field, the blocking model picks up on the patterns in labeled pairs and generates blocks that accommodate them.
A poorly learned blocking model is one of the most common causes of Zingg matching jobs being slow or running out of memory — because it generates blocks that are too large. If your blocking is too loose, all records end up in the same block and you're back to pairwise comparison. If it's too tight, you miss matches.
This is why Zingg provides the verifyBlocking phase as a diagnostic before committing to a full run:
./scripts/zingg.sh --phase verifyBlocking \ --conf conf.json \ --zinggDir /tmp/models
The output gives you two things:
If you see blocks with millions of records, that's a signal that your training data doesn't have enough variation, or that your blocking configuration has a systematic problem. The fix is usually to add more diverse labeled examples — specifically, pairs that represent the cases the current model is over-lumping — and retrain.
This diagnostic step takes minutes and can save hours of failed or incomplete match runs. It's worth making part of your standard workflow before any new matching configuration goes to production.
One practical technique that improves both recall and precision is using multiple blocking keys in combination, treating them as a union rather than an intersection.
Instead of requiring that two records share blocking key A and blocking key B, you compare records that share A or B. This means records that share a surname soundex but different postcodes (one might have moved) are still candidates. Records that share a postcode but slightly different surname soundex (due to phonetic edge cases) are still candidates.
The tradeoff is that the union of multiple blocking keys is larger than any individual key — more comparisons, but fewer missed matches. Getting this balance right for your data is partly what the verifyBlocking diagnostic helps with: you can observe how block sizes change as you add or modify blocking criteria.
When matching across two separate datasets (record linkage rather than deduplication), blocking has a slightly different character. You're not looking for pairs within a single dataset; you're looking for records in dataset A that match records in dataset B.
Zingg's link phase handles this directly — it takes each record from the first source and matches it against records in the remaining sources, using the same learned blocking model. The blocking model applies symmetrically: records that share blocking keys across sources are compared; those that don't are not.
One additional consideration for cross-source blocking: the two sources may have different field qualities. If source A has reliable postcodes but noisy surnames, and source B has reliable surnames but no postcodes, a blocking strategy that requires matching on both will miss many true matches. The learned model should handle this if the training data includes pairs that reflect this asymmetry — which is another argument for ensuring your labeled pairs represent the full diversity of your data.
Even with learned blocking, the fundamental tension remains: tighter blocking = faster but more false negatives; looser blocking = slower but more complete. There's no universal right answer — it depends on your data, your hardware, your latency requirements, and how much missed-match cost you can tolerate.
What good blocking gives you is a principled, evidence-based way to navigate this tradeoff. Rather than hand-tuning blocking rules based on your assumptions about the data, you let labeled pairs tell you what records need to be in the same block to find the true matches, and the model generalizes from there.
The verifyBlocking diagnostic gives you visibility into whether the generalization is working. And for cases where the model needs adjustment, adding more labeled pairs in the problem regions is the standard lever.
Up next: Part 4 — Thresholds, Scores, and Active Learning
← Part 2: The Noise Problem · Series index

