
Product

Solutions
Resources
About Us
Use Cases
Contact Us

.png)
As organizations collect more data and use more tools — in-house, cloud, partner-supplied — trusted information about customers, suppliers, partners, and other core entities becomes increasingly fragmented. Different systems capture the same entity differently. The same customer exists in the CRM under one name, in billing under a slightly different name, in the support system under an email alias, and in the loyalty program under a loyalty ID that nobody thought to cross-reference with anything else.
Without a unified view of these entities, analytics suffers in ways that compound quickly.
You cannot calculate customer lifetime value accurately when the same customer's transactions are split across multiple unlinked records. You cannot count new customers added per quarter when the same person appears as three new customers in three separate systems. You cannot build genuine personalization when the product recommendation engine has no idea that the person who just browsed winter coats in-store is the same person who bought a coat online six months ago.
The consequences extend beyond revenue. Compliance teams need accurate, unified entity definitions of suppliers and counterparties to verify they are not dealing with sanctioned individuals or organizations. Anti-Money Laundering (AML) and Know Your Customer (KYC) operations are built entirely on the ability to establish who an entity actually is — across every identity they may present across different accounts, transactions, or interactions.
Resolving multiple records without unique identifiers that all refer to the same real-world entity is the problem entity resolution exists to solve.
On the surface, entity resolution looks intuitive. Humans look at two records and immediately recognise whether they represent the same person. Surely a computer program can do the same?
The problem is that computers understand equality, not similarity. They can tell you that "Jon Smith" and "Jonathan Smith" are different strings. They cannot tell you that both represent the same person unless they have been taught what similarity looks like in your data.
Consider three records of the same customer arriving from three different source systems:
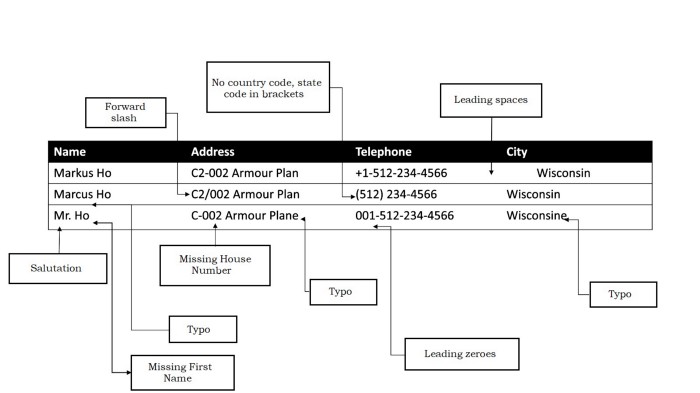
Not a single attribute matches exactly across all three records. Name formatting differs. The address is abbreviated in one and expanded in another. Phone numbers are formatted differently. The city is missing in one record. Yet any human would recognise these as the same person.
Now imagine crafting similarity rules in Python or SQL to match these records — and then doing the same for millions of records with thousands of variations. That is the problem entity resolution tools exist to solve.
Even with trusted identifiers like email addresses, the problem does not disappear. People use multiple email addresses — work, personal, school, and others. A shared email in one system and no email in another still requires fuzzy matching on other attributes to resolve the entity reliably. You cannot rely on trusted identifiers alone.
Graph databases like Neo4j are purpose-built for relationship analysis. Their native data model — nodes and edges — is a natural representation of entity relationships: this account is linked to that address; this person is connected to that organization; this transaction flows through this network of entities.

For entity analysis — understanding the network of relationships between known entities — graph databases are exceptional. Neo4j's Cypher query language makes traversing complex relationship networks intuitive. Its graph algorithms (connected components, community detection, PageRank, Louvain clustering) uncover patterns that would be invisible in a relational database: money laundering rings that span dozens of linked accounts, fraud networks connected through shared phone numbers, household relationships that span multiple addresses.
The natural approach to entity resolution in a graph database is to represent records as nodes and attributes as connected vertices. For three customer records, you would create a node for each record, then add attribute nodes for name, address, phone, and city. You define similarity metrics — cosine or Jaccard similarity for text — to create edges between similar attribute nodes. Then you use connected components to group all records connected through shared or similar attributes into entity clusters.
This approach works well for clean data with reliable shared identifiers. When the phone numbers match exactly, an edge is drawn. When the email addresses match, another edge connects them. Connected components then groups connected records together.
But real enterprise data is not clean. And when similarity has to be computed rather than matched exactly, the graph-only approach runs into significant limitations.
Defining similarity criteria is harder than it looks. For each attribute — name, address, phone, company name — you need to decide what "similar enough" means and implement it. Name similarity using Levenshtein distance handles simple typos but misses phonetic variants ("Smith" and "Smythe"), transpositions ("Jon Smith" and "Smith Jon"), and abbreviations ("IBM" and "International Business Machines"). Getting each attribute's similarity function right requires deep domain knowledge and constant tuning.
Combining attribute similarities into entity-level decisions is even harder. Even if you define reasonable similarity for each individual attribute, how do you combine them? If name similarity is high but address similarity is low, is it the same entity? The answer depends on the data quality of each attribute in your specific dataset, the entity type, and the use case — and there is no universal formula.
Scale becomes a wall. Pairwise similarity computation between all record pairs grows quadratically. Comparing every record's name to every other record's name, every address to every other address, is computationally prohibitive at enterprise scale even with distributed graph processing. Neo4j is exceptional at traversing known relationships efficiently. Computing whether relationships should exist in the first place — at scale, with fuzzy criteria — is not what it was built for.
The result is a practical ceiling. Graph-only entity resolution works well for small datasets with good-quality shared identifiers. For large-scale enterprise data with real-world variation and no reliable shared keys, it does not scale without a specialized entity resolution layer doing the heavy lifting.
The better architecture: use Zingg for entity resolution, then load the resolved entities into Neo4j for relationship analysis. Each tool does what it is best at.
Zingg is a specialized, open-source ML-based entity resolution framework. (Full disclosure: I am the founder of Zingg.) Rather than requiring you to define similarity criteria for each attribute, Zingg learns the matching pattern from a small set of labeled examples drawn from your specific data. You label 30–40 record pairs as match or non-match through Zingg's interactive labeler, and Zingg automatically determines the appropriate similarity thresholds and attribute weights for your dataset.
Step 1: Configure. Build a configuration file specifying your input data locations, output locations, and which fields to use for matching.
Step 2: Train. Run Zingg's findTrainingData phase to generate representative sample pairs from your data. Label them as matches or non-matches through the interactive labeler. Zingg uses active learning to select the pairs that will most efficiently teach the model — typically 30–40 labeled pairs are sufficient to build a production-quality model.
Step 3: Match. Run the match phase to apply the trained model to your full dataset. Zingg's learned blocking model reduces the comparison space to typically 0.05–1% of all possible record pairs, making large-scale matching tractable without requiring database tuning.
The output is a table of your original records, each annotated with a cluster identifier and match probability scores for each resolved pair. Records sharing a cluster identifier represent the same real-world entity.
In Zingg Enterprise, each cluster is also assigned a persistent ZINGG_ID — a stable identifier that does not change across subsequent runs, even as underlying records are updated or new records arrive.
The Zingg output loads naturally into Neo4j. Each entity cluster becomes a node — or the ZINGG_ID becomes the primary node identifier for the entity. The individual source records become nodes linked to their entity node. The probability scores from Zingg's match output become edge properties, preserving the confidence level of each link for downstream analysis.

Once the resolved entity graph is in Neo4j, you can import your transactional data and build the relationship layer that Neo4j is designed to analyze: transactions between entities, shared attributes, network connections, organizational hierarchies.
The advantages of using Zingg for resolution before loading into Neo4j:
No attribute-level similarity engineering required. Zingg learns appropriate similarity from your labeled data. You do not define separate similarity functions for names, addresses, phone numbers, and company names.
No attribute combination problem. Zingg's classifier determines the right way to combine attribute-level signals into an entity-level match decision for your specific data. You do not specify weights or thresholds manually.
Scale is built in. Zingg's blocking model reduces comparisons to a small fraction of the full problem space. You are not computing pairwise similarity across all record pairs — only across the candidate pairs where a match is plausible. This makes resolution feasible at tens or hundreds of millions of records.
Grouping is handled automatically. Zingg's clustering produces entity groups directly. You do not need to implement connected components logic or community detection to group linked records — that is done before the data reaches Neo4j.
Deterministic and probabilistic matching work together. Where trusted identifiers exist — email, SSN, passport number — Zingg Enterprise's deterministic matching resolves those records definitively. Where they are absent or inconsistent, probabilistic ML-based matching handles the rest. Both feed into the same entity clusters and the same ZINGG_ID, so the graph node represents a complete entity regardless of which matching method linked each source record.
AML compliance requires not just identifying who an entity is, but mapping the network of relationships between entities — accounts, beneficial owners, transactions, shared addresses. This is precisely what Neo4j is designed for.
But it only works if the entities are correctly resolved in the first place. A money laundering ring that operates through accounts opened under slight variations of the same name is invisible to any system that treats each account as a separate entity. Zingg resolves those accounts into a single entity. Neo4j then maps the network of transactions and relationships across that entity, making the pattern visible.
KYC workflows that combine Zingg's identity resolution with Neo4j's relationship mapping can screen against sanctions lists, detect previously flagged identities presenting under new names, and map connections between applicants and high-risk entities — all with confidence in the underlying entity identity.
Fraudsters rely on fragmentation. An insurance fraudster files claims for the same property under slightly different names and addresses across different policy periods. A payment fraudster opens multiple accounts with minor variations in their details. A synthetic identity fraudster combines real and fabricated attributes across accounts.
Zingg resolves the fragmented records. Neo4j maps the fraud network. Together, they detect patterns that neither could find alone.
Zingg builds the unified customer identity — recognizing the same customer across CRM, e-commerce, loyalty, and in-store systems. Neo4j adds the relationship layer: household membership, account ownership, cross-product relationships, referral networks.
The combination enables a Customer 360 that is not just a unified record but a connected graph of the customer's full relationship with the business and with other related entities.
This is the use case that has become dramatically more compelling with the rise of LLMs and Retrieval-Augmented Generation.
A standard RAG system retrieves records based on embedding similarity and uses them as context for an LLM. The problem: when underlying records have fragmented entity data, retrieval is unreliable. A query for "John Smith" might retrieve records for "J. Smith," "Jon Smith," and "John A. Smith" as separate contexts — or miss some entirely. The LLM reasons about an incomplete, inconsistent picture of the entity and produces unreliable output.
Identity RAG solves this by resolving entities first, then building a knowledge graph that retrieval operates against. The ZINGG_ID becomes the retrieval anchor: rather than searching across fragmented records by string similarity, the system retrieves all records associated with a ZINGG_ID and presents a unified, complete entity context to the LLM.
Zingg + Neo4j is a natural architecture for Identity RAG:
The result is AI that actually knows who it is reasoning about. For agentic workflows operating on customer, patient, supplier, or financial entity data, this is the difference between a useful agent and one that confidently acts on wrong information.
See the Zingg + LangChain Identity RAG guide for a detailed implementation walkthrough.
One of the most common gaps in Zingg + Neo4j implementations is freshness. If Zingg runs as a one-time batch job, the knowledge graph reflects the state of data at that moment. New records, updated records, and newly-linked accounts that arrive after the batch run create drift between the graph and reality.
Zingg Enterprise's incremental resolution addresses this directly. Rather than re-running the full matching pipeline when data changes, the incremental flow processes only new and updated records against the existing entity graph:
Because ZINGG_IDs are preserved through all of these operations, Neo4j queries and downstream systems that reference entities by ZINGG_ID continue to work correctly without any updates on their end. The graph stays current at the pace of your operational data.
ZinggNeo4jDoesEntity resolution at scale — blocking, ML-based matching, clustering, persistent ZINGG_IDRelationship analysis — graph traversal, network detection, community algorithmsHandlesData variation, fuzzy matching, attribute similarity, scaleComplex queries over known relationships, network patterns, connected subgraphsProducesResolved entity clusters with persistent ZINGG_IDsInsights from the entity relationship graph
The combination eliminates the hardest parts of each tool's standalone limitations: Zingg removes the need to define similarity criteria in Neo4j; Neo4j removes the need to implement relationship analysis logic on top of Zingg's tabular output.
For technical implementation details:
Explore and try: - Zingg on GitHub — open source entity resolution - Zingg Enterprise — persistent ZINGG_ID, incremental flow, deterministic matching, native Snowflake - ZINGG_ID feature - Incremental flow feature - Deterministic matching feature - Zingg documentation - Contact us
Further reading on this blog: - The What and Why of Entity Resolution - The ZINGG_ID: A Persistent Identifier for Your Entity Graph - Incremental Identity Resolution: Keeping Your Entity Graph Current - Deterministic vs. Probabilistic Matching: Why You Need Both - Customer 360: What It Really Takes to Build One - A Guide to Agile Data Mastering with AI

